If you are in IT Operations in any role, you have probably come across either Splunk or ELK, or both. These are two heavyweights in the field of Operational Data Analytics. In this blog post, I’m going to share with you what I feel about these two excellent products based on my years of experience with them.
The problem Splunk and ELK are trying to solve: Log Management
While there are fancier terms such as Operational Data Intelligence, Operational Big Data Analytics and Log data analytics platform, the problem both Splunk and ELK are trying to solve is Log Management. So, what’s the challenge with Log management?
Logs, logs, logs and more logs
The single most important piece of troubleshooting data in any software program is the log generated by the program. If you have ever worked with vendor support for any software product, you have been inevitably asked to provide – you guessed it, Log files. Without the log files, they really can’t see what’s going on.
Logs not only contains information about how the software program runs, they may contain data that are valuable to business as well. Yeap, that’s right. For instance, you can retrieve wealth of data from your Web Server access logs to find out things like geographical dispersion of your customer base, most visited page in your website, etc.
If you are running only a couple of servers with few applications running on them, accessing and managing your logs are not a problem. But in an enterprise with hundreds and even thousands of servers and applications, this becomes an issue. Specifically,
- There are thousands of log files.
- The size of these log files run in Giga or even Terra bytes.
- The data in these log files may not be readily readable or searchable (unstructured data)
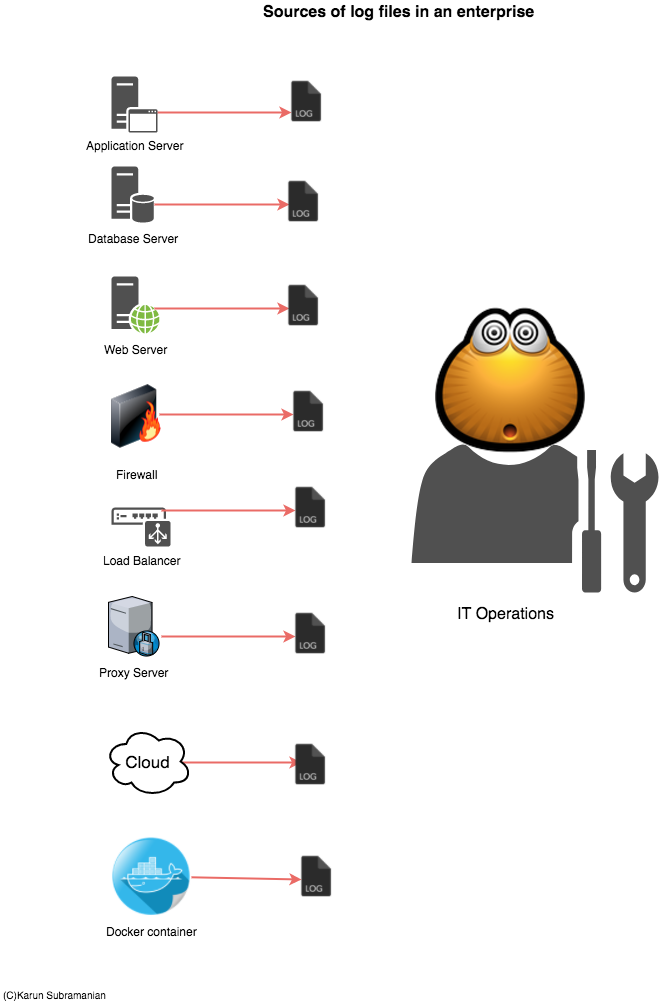
Both Splunk and ELK attempt to solve the problem of managing ever growing Log data. In essence, they supply a scalable way to collect and index log files and provide a search interface to interact with the data. In addition, they provide a way to secure the data being collected and enable users to create visualizations such as reports, dashboards and even Alerts.
Now that you know the problem Splunk and ELK are attempting to solve, let’s compare them and find how they are achieving this. I’m going to compare them in 4 areas as follows:
Technology
Cost
Features
Learning Curve for the operations team
Got it ? I can’t wait to share. Let’s dive in.

VS
![]()