One of the most frequently asked questions in Splunk is the difference between universal forwarder and heavy forwarder. In this post, I’ll explain the difference and suggest when to use certain type of forwarder. Let’s roll.
What is a Splunk Forwarder?
A Splunk forwarder reads data from a data source and forwards to another Splunk or Non-Splunk process. It is one of the core components of Splunk platform, the others being Splunk indexer and Splunk search head. Figure 1 shows a super high level architecture of Splunk platform:
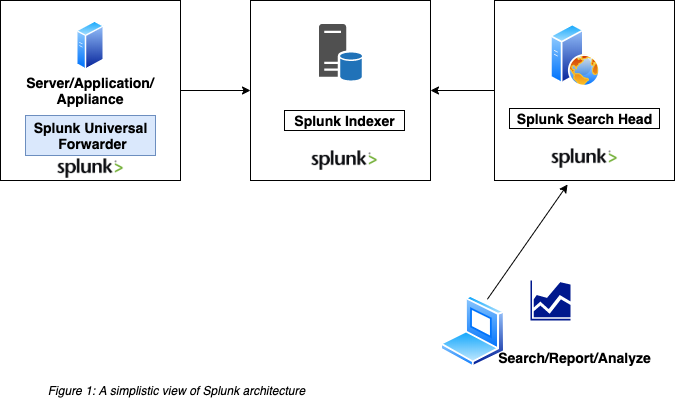
While there are many ways to get data into Splunk platform, Splunk Universal Forwarder is by far the most common way to get data in. The other ways of getting data in, sorted by the popularity, based strictly on my experience:
- Splunk Heavy Forwarder
- HTTP Event Collector
- TCP Input
- Syslog input
- Splunk Apps such as DBConnect
- Custom modular inputs
- Scripted input
There are two types of Splunk forwarders, namely Universal Forwarder and Heavy Forwarder.
So, What does the Universal Forwarder do Anyway?
The basic yet the crucial task that Universal Forwarders perform is to collect and send the data to other Splunk processes, typically to the Splunk Indexers . At the indexers, the data is broken in to Events and indexed for searching. Universal Forwarders are typically installed on the machines where the source data resides. Examples include application servers, web servers, directory servers and so on.
The Splunk Universal Forwarder binary is somewhat similar to that of Splunk Indexer or Search Head, but it is stripped down bare-bone version. It is very light weight and designed to run on production systems.
Note: One major complaint you may get from application owners is about the resource utilization of Splunk Universal Forwarders. They are skeptical that Universal Forwarder will take down their server, or perhaps take up all the resources and leave nothing for their applications. While nothing is impossible in the complex world of IT, I can confidently say that Splunk Universal Forwarder is one of the most efficient software you will find out there. The only reason Universal Forwarder may consume significant resources (4gb+ memory) is when thousands of files are being configured to ingest.
The Universal Forwarder performs the following when collecting and sending data:
- Reads the input data source (often files and directories)
- Keeps track of the progress of the reading (it does that by storing hash values in a special index called fishbucket which resides on the Universal Forwarder)
- Sets the meta fields in the data such as
- host
- source
- sourcetype
- index
- Optionally performs encryption
- Optionally performs compression
- Runs scripts for scripted input
- Performs parsing for structured data such as CSV files.
Note: Splunk Universal Forwarders perform very minimal processing. The only time it does any parsing is when the input is a structured file such as CSV files.
The primary configuration files that drive the functionality of a Universal Forwarder are inputs.conf and outputs.conf.
In Unix servers, the Splunk Universal Forwarder runs as a process named splunkd. You can optionally configured splunkd to run as systemd service. On Windows serves, Universal Forwarder is typically installed as a Windows service.
You do not need a separate license to run a Splunk Universal Forwarder. It comes with a built-in license.
That’s Fine. But What in the World is a Splunk Heavy Forwarder?
I don’t blame the frustration in your question. It is confusing, is it not? HEAVY Forwarder? So, let’s put your frustration to end.
The major difference between Splunk Universal Forwarder and Splunk Heavy Forwarder is PARSING & INDEXING. Splunk Universal Forwarders do NOT parse the data (except when the data is structured files like CSV). Heavy Forwarders parse the data, which includes the following:
- Perform Line breaking
- Perform Line merging
- Extracts Time stamps
- Extracts Index-time fields
The Splunk Heavy Forwarders can optionally index the data as well, even though most of times, they forward the data to the indexer where the data is written to the index. Note that when the data comes from a Heavy Forwarder, indexers do NOT parse the data again. Parsing happens at the Heavy Forwarders.
The primary configuration files that drive the functionality of a Heavy Forwarder are inputs.conf, outputs.conf, props.conf, transforms.conf.
Generally Heavy Forwarders are used as intermediary between Universal Forwarders and indexers. For example, multiple Universal Forwarders can send data to one Heavy Forwarder, and it in turn send the data to Indexers. Heavy Forwarders can also send data to non-Splunk destinations, such as a big-data datalake. Heavy Forwarders are also used to run Splunk add-ons that receive data from external sources. For example:
Splunk DBConnect
Splunk HTTP Event collector
Splunk Salesforce Add-on to pull data from Salesforce
Splunk New Relic Add-on to pull data from New Relic
Figure 2 shows a typical Splunk Heavy Forwarder setup:
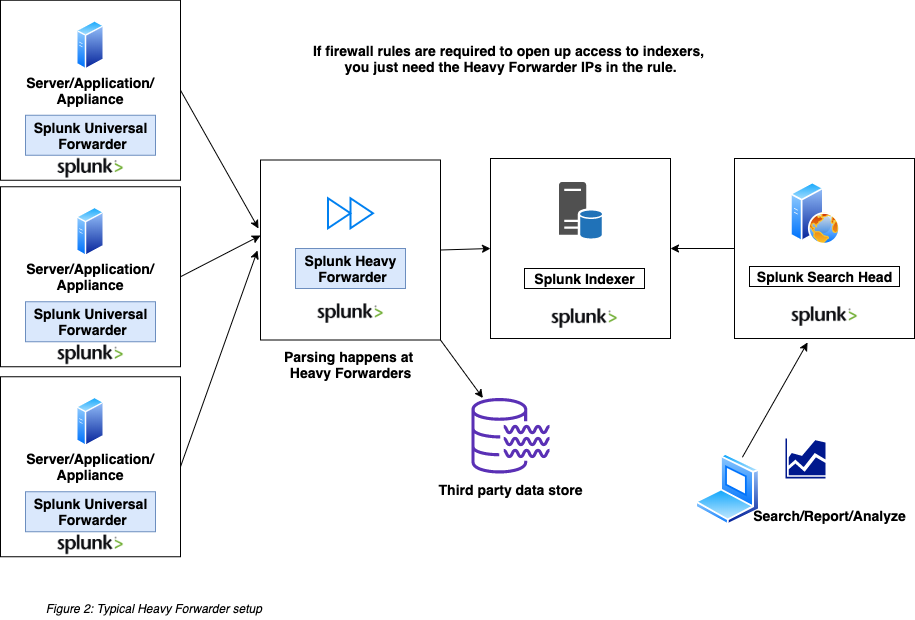
Unlike Universal Forwarders, Splunk Heavy Forwarders do require a Forwarder License. If the Heavy Forwarder also needs to index the data, it needs to have access to Splunk Enterprise license stack.
To sum it up, here are the differences between Universal Forwarder and Heavy Forwarder:
| Universal Forwarder | Heavy Forwarder |
| Splunk Universal Forwarder binary | Splunk Enterprise binary (used by Indexers, Search Heads and other Splunk processes) |
| Collects and sends data to Indexers or Heavy Forwarders | Receives data from Universal Forwarders and sends it to Indexers, or other third party data stores. Acts as intermediary in routing data |
| Does not parse data (except when the data is structured such as CSV) | Parses data, which includes Line breaking, timestamp extraction and extracting index-time fields |
| Cannot index data | Can optionally index data |
| Built-in license. No additional license required | Forwarder license required. Requires access to Enterprise license stack if indexing is required. |
Use Universal Forwarder when you need to collect data from a server or application and send it to Indexers. This is the most common way to get data into Splunk. Use Heavy Forwarder when you need to use an intermediary between Universal Forwarders and Indexers. Note that when Heavy Forwarders are used, data parsing happens in the Heavy Forwarders. Also use Heavy Forwarders when you need to run add-ons such as Splunk DBConnect. Finally, if you need forward data to a third-party data store, use Heavy Fowarders.
Good luck.
Hi Karun, thanks for explaining the difference between universal and heavy forwarders in such a detail! Was very helpful! I stumbled upon your site after going thru your intro video for Splunk Enterprise Certified Admin intro course in PluralSight. That was helpful too, thanks!