One of the most powerful features of Splunk, the market leader in log aggregation and operational data intelligence, is the ability to extract fields while searching for data. Unfortunately, it can be a daunting task to get this working correctly. In this article, I’ll explain how you can extract fields using Splunk SPL’s rex command. I’ll provide plenty of examples with actual SPL queries. In my experience, rex is one of the most useful commands in the long list of SPL commands. I’ll also reveal one secret command that can make this process super easy. By fully reading this article you will gain a deeper understanding of fields, and learn how to use rex command to extract fields from your data.
What is a field?
A field is a name-value pair that is searchable. Virtually all searches in Splunk uses fields. A field can contain multiple values. Also, a given field need not appear in all of your events. Let’s consider the following SPL.
index=main sourcetype=access_combined_wcookie action=purchaseThe fields in the above SPL are “index”, “sourcetype” and “action”. The values are “main”, “access_combined_wcookie” and “purchase” respectively.
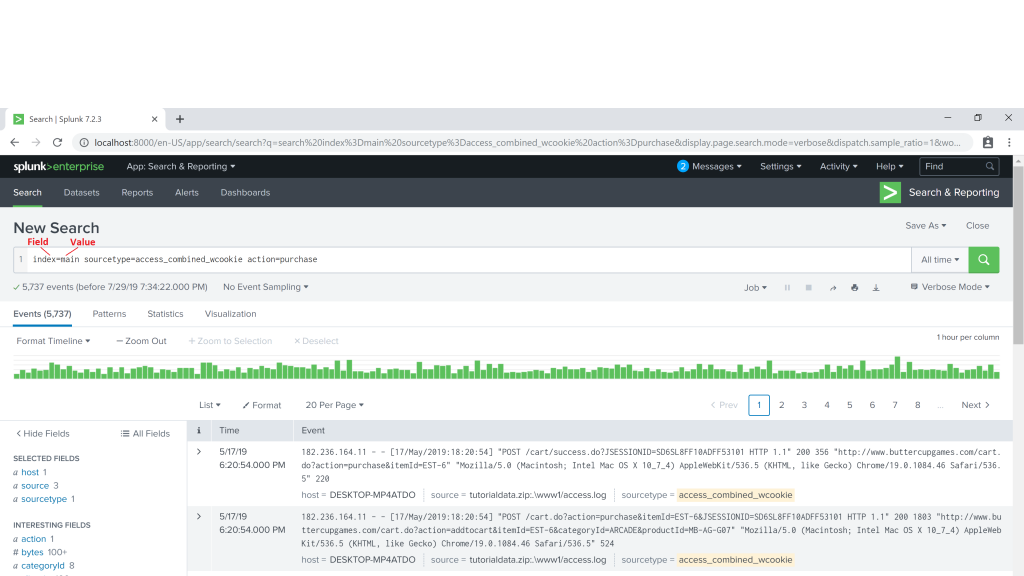
Fields turbo charge your searches by enabling you to customize and tailor your searches. For example, consider the following SPL
index=web sourcetype=access_combined status>=500 response_time>6000The above SPL searches the index web which happens have web access logs, with sourcetype equal to access_combined, status grater than or equal to 500 (indicating a server side error) and response_time grater than 6 seconds (or 6000 milli seconds). This kind of flexibility in exploring data will never be possible with simple text searching.
How are fields created?
There is some good news here. Splunk automatically creates many fields for you. The process of creating fields from the raw data is called extraction. By default Splunk extracts many fields during index time. The most notable ones are:
index
host
sourcetype
source
_time
_indextime
splunk_server
You can configure Splunk to extract additional fields during index time based on your data and the constraints you specify. This process is also known as adding custom fields during index time. This is achieved through configuring props.conf, transforms.conf and fields.conf. Note that if you are using Splunk in a distributed environment, props.conf and transforms.conf reside on the Indexers (also called Search Peers) while fields.conf reside on the Search Heads. And if you are using a Heavy Forwarder, props.conf and transforms.conf reside there instead of Indexers.
While index-time extraction seems appealing, you should try to avoid it for the following reasons.
- Indexed extractions use more disk space.
- Indexed extractions are not flexible. i.e. if you change the configuration of any of the indexed extractions, the entire index needs to be rebuilt.
- There is a performance impact as Indexers do more work during index time.
Instead, you should use search-time extractions. Schema-on-Read, in fact, is the superior strength of Splunk that you won’t find in any other log aggregation platforms. Schema-on-Write, which requires you to define the fields ahead of Indexing, is what you will find in most log aggregation platforms (including Elastic Search). With Schema-on-Read that Splunk uses, you slice and dice the data during search time with no persistent modifications done to the indexes. This also provides the most flexibility as you define how the fields should be extracted.
Many ways of extracting fields in Splunk during search-time
There are several ways of extracting fields during search-time. These include the following.
- Using the Field Extractor utility in Splunk Web
- Using the Fields menu in Settings in Splunk Web
- Using the configuration files
- Using SPL commands
- rex
- extract
- multikv
- spath
- xmlkv/xpath
- kvform
For Splunk neophytes, using the Field Extractor utility is a great start. However as you gain more experience with field extractions, you will start to realize that the Field extractor does not always come up with the most efficient regular expressions. Eventually, you will start to leverage the power of rex command and regular expressions, which is what we are going to look in detail now.
What is rex?
rex is a SPL (Search Processing Language) command that extracts fields from the raw data based on the pattern you specify using regular expressions.
The command takes search results as input (i.e the command is written after a pipe in SPL). It matches a regular expression pattern in each event, and saves the value in a field that you specify. Let’s see a working example to understand the syntax.
Consider the following raw event.
Thu Jan 16 2018 00:15:06 mailsv1 sshd[5801]: Failed password for invalid user desktop from 194.8.74.23 port 2285 ssh2
The above event is from Splunk tutorial data. Let’s say you want to extract the port number as a field. Using the rex command, you would use the following SPL:
index=main sourcetype=secure
| rex "port\s(?<portNumber>\d+)\s"
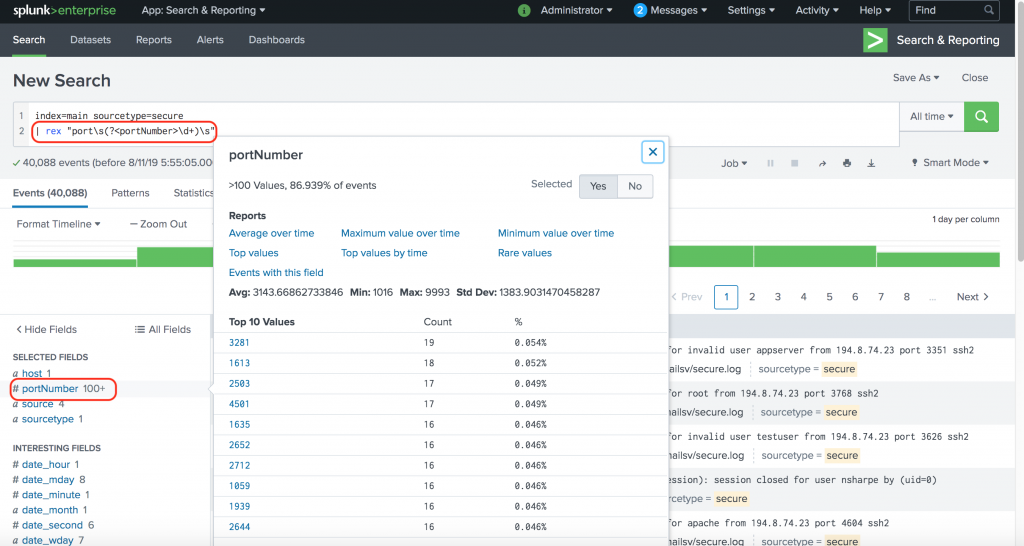
Once you have port extracted as a field, you can use it just like any other field. For example, the following SPL retrieves events with port numbers between 1000 and 2000.
index=main sourcetype=secure | rex "port\s(?<portNumber>\d+)\s"
| where portNumber >= 1000 AND portNumber < 2000
Note: rex has two modes of operation. The sed mode, denoted by option mode=sed lets you replace characters in an existing field. We will not discuss sed more in this blog.
Note: Do not confuse the SPL command regex with rex. regex filters search results using a regular expression (i.e removes events that do not match the regular expression provided with regex command).
Syntax of rex
Let’s unpack the syntax of rex.
rex field=<field> <PCRE named capture group>
The PCRE named capture group works the following way:
(?<name>regex)
The above expression captures the text matched by regex into the group name.
Note: You may also see (?P<name>regex) used in named capture groups (notice the character P). In Splunk, you can use either approach.
If you don’t specify the field name, rex applies to _raw (which is the entire event). Specifying a field greatly improves performance (especially if your events are large. Typically I would consider any event over 10-15 lines as large).
There is also an option named max_match which is set to 1 by default i.e, rex retains only the first match. If you set this option to 0, there is no limit to the number of matches in an event and rex creates a multi valued field in case of multiple matches.
As you can sense by now, mastering rex means getting a good handle of Regular Expressions. In fact, it is all out regular expressions when it comes to rex. It is best learned through examples. Let’s dive right in.
Learn rex through examples
Extract a value followed by a string
Raw Event:
Thu Jan 16 2018 00:15:06 mailsv1 sshd[5258]: Failed password for invalid user testuser from 194.8.74.23 port 3626 ssh2Extract a field named username that is followed by the string user in the events.
index=main sourcetype=secure
| rex "user\s(?<username>\w+)\s"
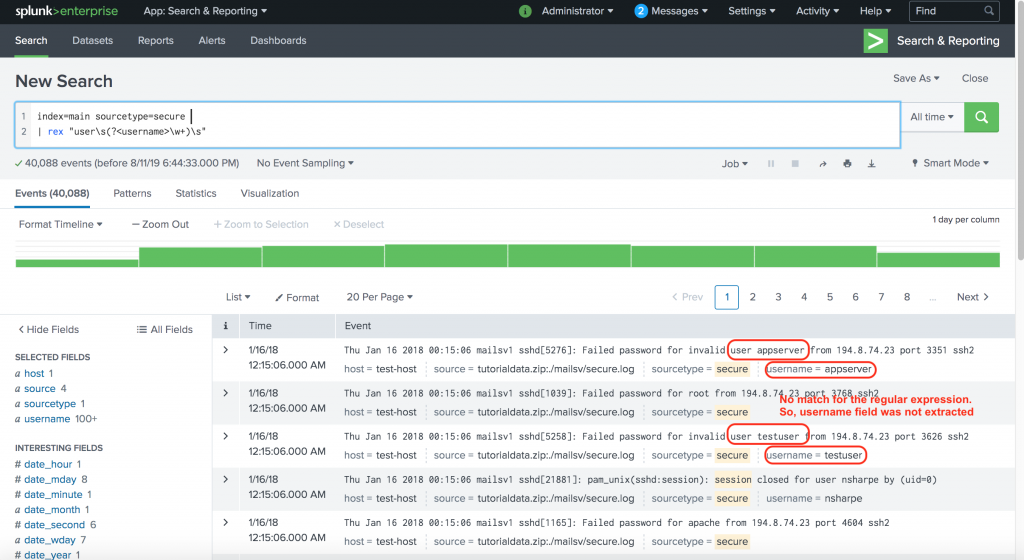
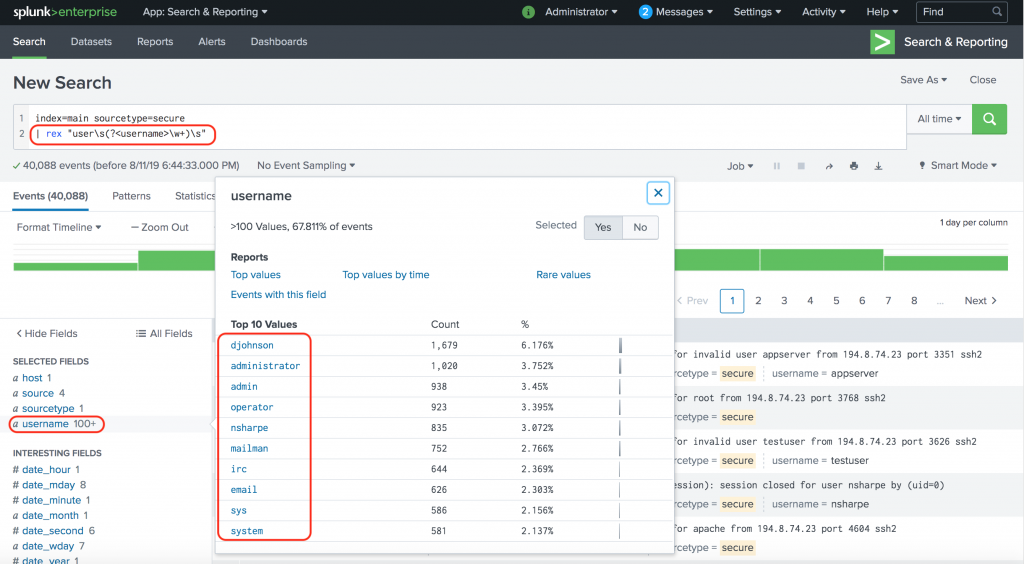
Isn’t that beautiful?
Now, let’s dig deep in to the command and break it down.
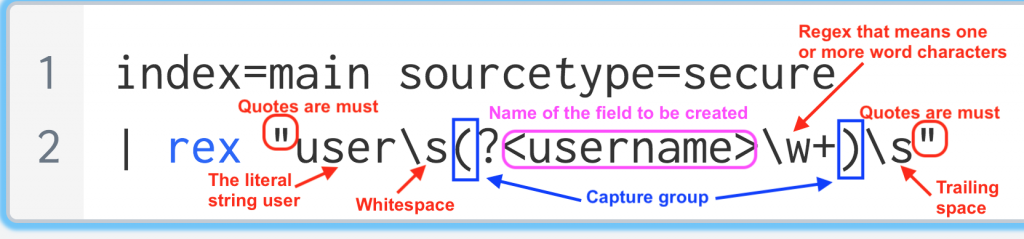
Extract a value based a pattern of the string
This can be super handy. Extract java exceptions as a field.
Raw Event:
08:24:42 ERROR : Unexpected error while launching program.
java.lang.NullPointerException
at com.xilinx.sdk.debug.core.XilinxAppLaunchConfiguration
Delegate.isFpgaConfigured(XilinxAppLaunchConfigurati
onDelegate.java:293)
Extract any java Exception as a field. Note that java exceptions have the form java.<package hierarchy>.<Exception>. For example:
java.lang.NullPointerException
java.net.connectexception
javax.net.ssl.SSLHandshakeException
So, the following regex matching will do the trick.
java\..*Exception
Explanation:
java: A literal string java
\. : Backslash followed by period. In regex, backslash escapes the following character, meaning it will interpret the following character as it is. Period (.) stands for any character in regex. In this case we want to literally match a period. So, we escape it.
.* : Period followed by Star (*). In regex, * indicates zero or more of the preceding character. Simply .* means anything.
Exception: A literal string Exception.
Our full blown SPL looks like this:
index=main sourcetype=java-logs
| rex "(?<javaException>java\..*Exception)"
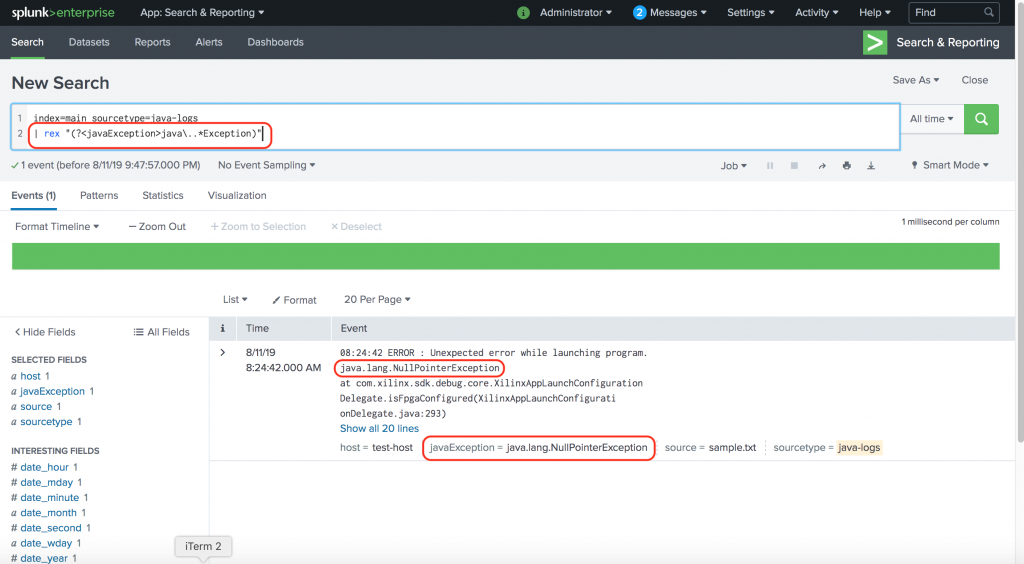
Let’s add some complexity to it. Let’s say you have exceptions that look like the following:
javax.net.ssl.SSLHandshakeException
Notice the “x” in javax ? How can we account for x ? Ideally what we want is to have rex extract the java exception regardless of javax or java. Thanks to the character class and “?” quantifier.
java[x]?\..*Exception
Let us consider new raw events.
08:24:42 ERROR : Unexpected error while launching program.
java.lang.NullPointerException
at com.xilinx.sdk.debug.core.XilinxAppLaunchConfiguration
08:24:43 ERROR : javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested targetOur new SPL looks like this:
index=main sourcetype=java-logs1
| rex "(?<javaException>java[x]?\..*Exception)"
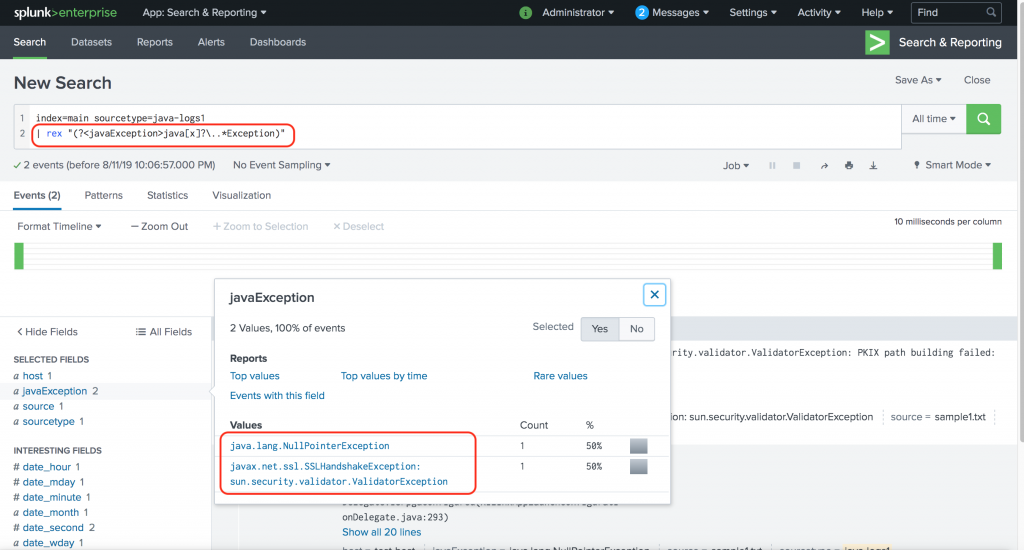
That’s much better. Our extracted field javaException captured the exception from both the events.
Wait a minute. Is something wrong with this extraction,
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException
Apparently, the extraction captured two exceptions. The raw event looks like this:
08:24:43 ERROR : javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
Apparently the regex java[x]?\..*Exception is matching all the way up to the second instance of the string “Exception”.
This is called greedy matching in regex. By default the quantifiers such as “*” and “+” will try to match as many characters as possible. In order to force a ‘lazy’ behaviour, we use the quantifier “?”. Our new SPL looks like this:
index=main sourcetype=java-logs1
| rex "(?<javaException>java[x]?\..*?Exception)"
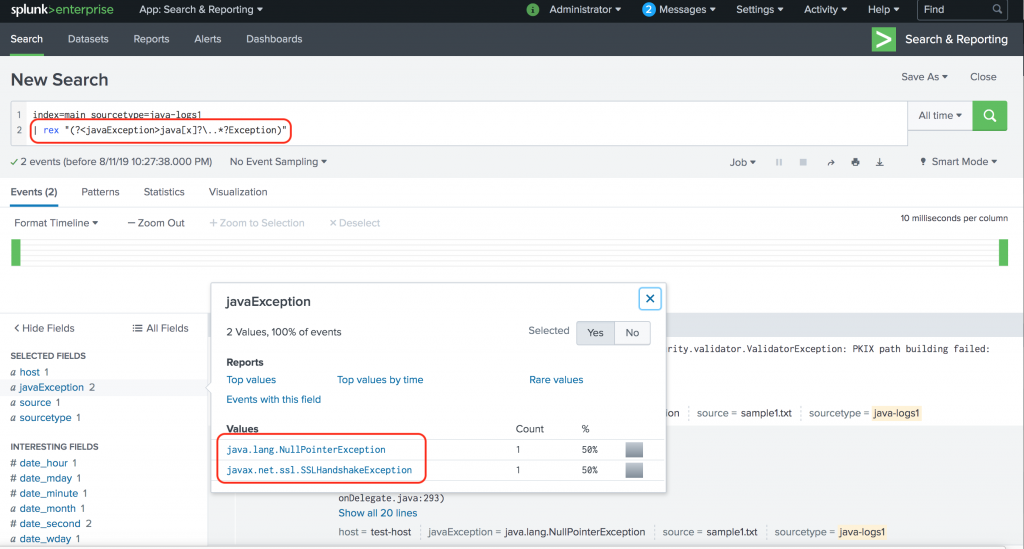
That’s much much better!
Extract credit card numbers as a field
Let’s say you have credit card numbers in your log file (very bad idea). Let’s say they all the format XXXX-XXXX-XXXX-XXXX, where X is any digit. You can easily extract the field using the following SPL
index="main" sourcetype="custom-card"
| rex "(?<cardNumber>\d{4}-\d{4}-\d{4}-\d{4})"
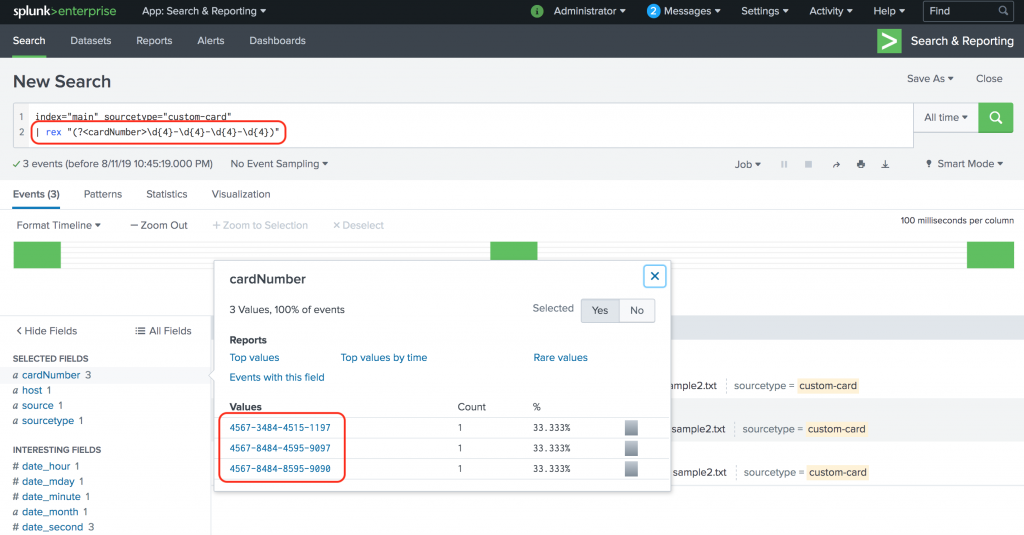
The {} helps with applying a multiplier. For example, \d{4} means 4 digits. \d{1,4} means between 1 and 4 digits. Note that you can group characters and apply multipliers on them too. For example, the above SPL can be written as following:
index="main" sourcetype="custom-card"
| rex "(?<cardNumber>(\d{4}-){3}\d{4})"
Extract multiple fields
You can extract multiple fields in the same rex command.
Consider the following raw event
Thu Jan 16 2018 00:15:06 mailsv1 sshd[5276]: Failed password for invalid user appserver from 194.8.74.23 port 3351 ssh2
The above event is from Splunk tutorial data.
You can extract the user name, ip address and port number in one rex command as follows:
index="main" sourcetype=secure
| rex "invalid user (?<userName>\w+) from (?<ipAddress>(\d{1,3}.){3}\d{1,3}) port (?<port>\d+) "
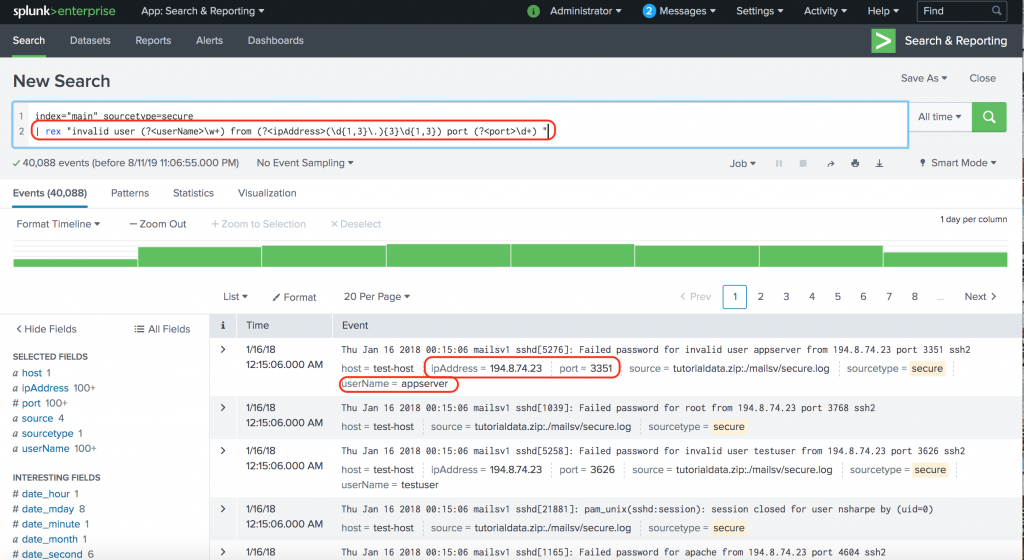
Also note that you can pipe the results of the rex command to further reporting commands. For example, from the above example, if you want to find the top user with login errors, you will use the following SPL
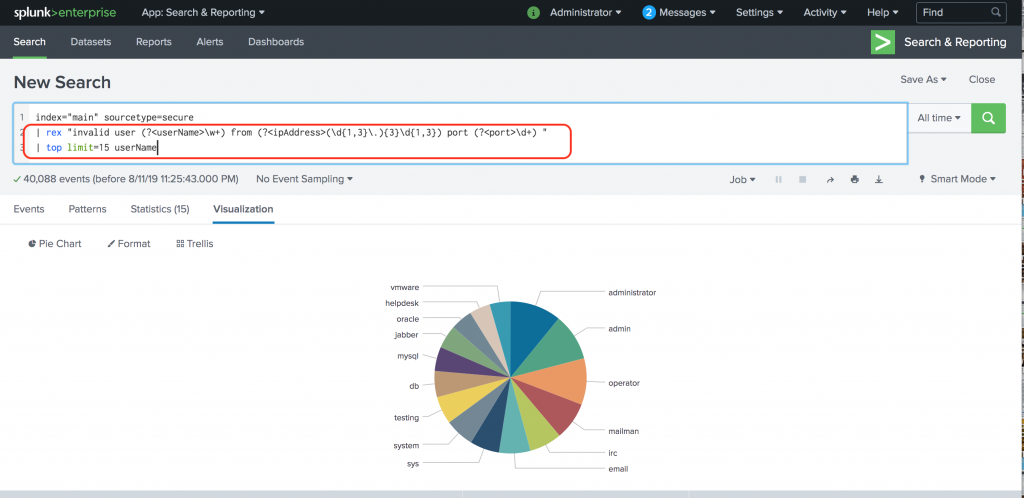
index="main" sourcetype=secure
| rex "invalid user (?<userName>\w+) from (?<ipAddress>(\d{1,3}.){3}\d{1,3}) port (?<port>\d+) "
| top limit=15 userName
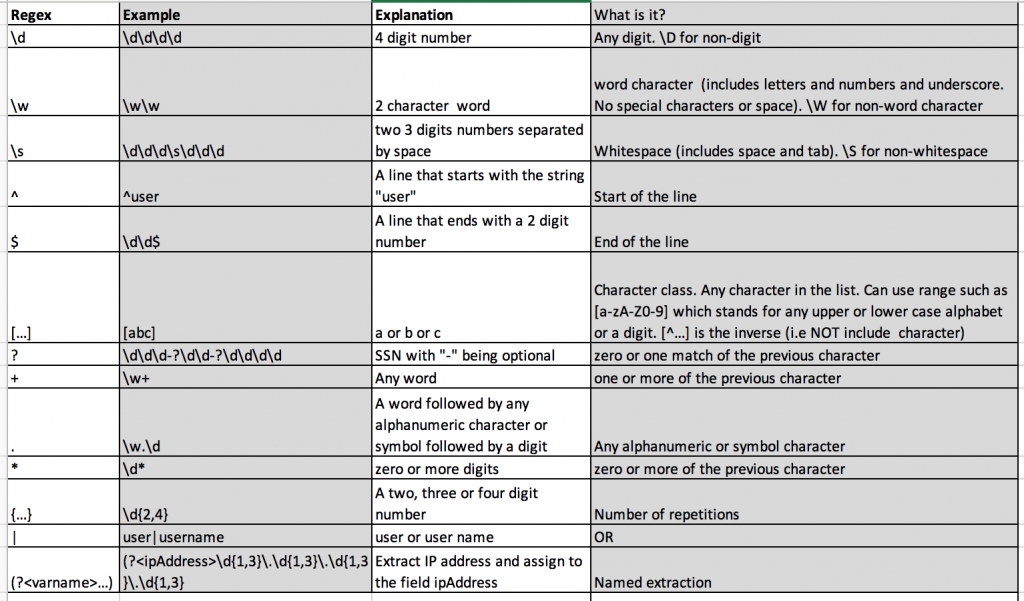
Regular Expression Cheat-Sheet
A short-cut
Regex, while powerful, can be hard to grasp in the beginning. Fortunately, Splunk includes a command called erex which will generate the regex for you. All you have to do is provide samples of data and Splunk will figure out a possible regular expression. While I don’t recommend relying fully on erex, it can be a great way to learn regex.
For example use the following SPL to extract IP Address from the data we used in our previous example:
index="main" sourcetype=secure
| erex ipAddress examples="194.8.74.23,109.169.32.135"
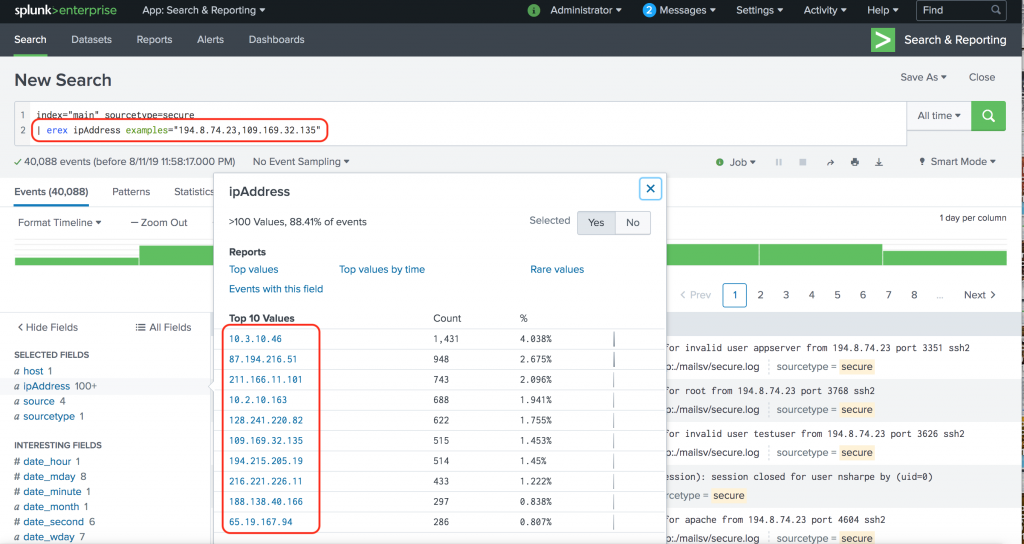
Not bad at all. Without writing any regex, we are able to use Splunk to figure out the field extraction for us. Here is the best part: When you click on “Job” (just above the Timeline), you can see the actual regular expression that Splunk has come up with.
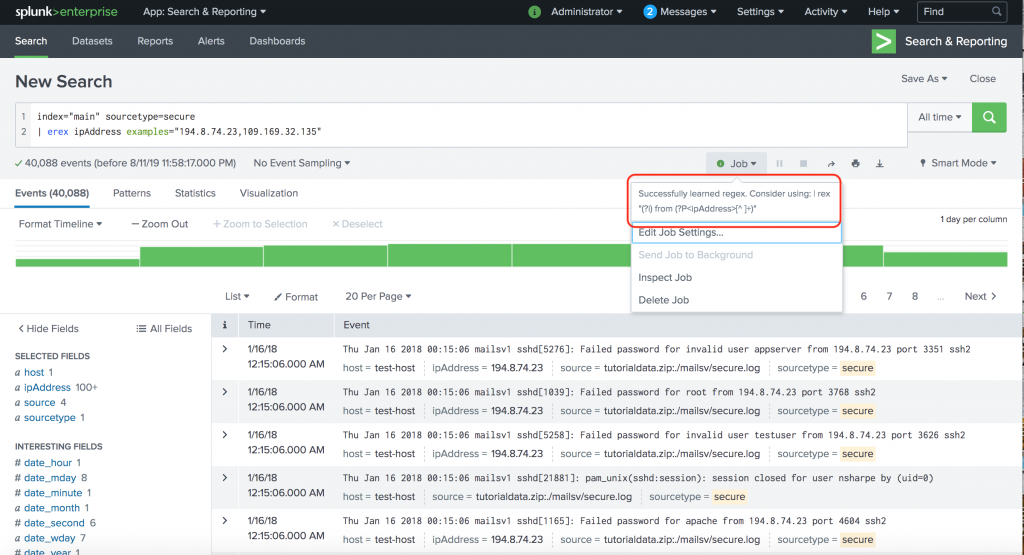
Successfully learned regex. Consider using: | rex "(?i) from (?P[^ ]+)"
I’ll let you analyze the regex that Splunk had come up with for this example :-). One hint: The (?i) in the above regex stands for “case insensitive”
That brings us to the end of this blog. I hope you have become a bit more comfortable using rex to extract fields in Splunk. Like I mentioned, it is one of the most powerful commands in SPL. Feel free to use as often you need. Before you know, you will be helping your peers with regex.
Happy Splunking!
Thank you for your explanations, they are very well written and easily understandable.
Thanks so much for the write up! I learned a lot.
Explained in a simple fashion any novice can understand. Well done.
Hi ,
i m new for splunk, I need one help, How to write query for below cases using rex,
example-
field name value
url https://www.tutorial.com/goto/splunk=ab1234567
https://www.tutorial.com/goto/splunk=ab12345
https://www.tutorial.com/goto/splunk=ab12356
https://www.tutorial.com/goto/splunk=ab12345678
Q) need to filter out which is splunk having value length is 7 (ab12345) in url value
could you please help me out
let me know if you any concern
Hi, Nagendra.
If you simply want to filter, use the regex command at the end of your search as follows.
… | regex “splunk=\w{7}$”
The above regex matches lines that end with the string “splunk=” followed by 7 characters (letter,number or _).
Good luck.
Explained with really nice examples. Thank you 🙂
Explained very well , with adequate examples…Glad to find this page..
Thank you so much, I’ve spent 3 days pounding my head against my keyboard! Instantly figured out my problem after reading this!!!!!
Thank you so much for the explanation on using regex. The Splunk documentation was “lacking” on teaching the use of this very powerful tool. This has provided a breakthrough on the data that I can collect and transform!
I am new to splunk queries,
I need help on this.How to display this log info using query *”log”:”2023-08-24 02:35:43 BST [INFO] -*
Hi, Deepthi.
Can you please provide some more details? Are you trying to extract some value from you search results as a field?
I’m not sure what you mean when you say “How to display this log info using query”.
Thanks.
Nice work! Splunk should employ you to write tutorials, much better for a novice than some of theirs! Thanksgiving