To the uninitiated, we are not talking about Docker clothing company, which makes the popular Men’s Khakis. What we are talking about is the Docker that has changed the way Software Applications are built, shipped and run. You have probably heard about Docker and how cool it is, but never really understood fully. And you are itching to finally sit down and read about it. You have come to the right place. In this blog post, I’m going to demystify Docker for you. By reading this guide fully, you will understand,
- What the heck is Docker?
- What makes Docker so invaluable and indispensable?
- How to install Docker on your PC or MAC?
- How to build images and run containers
- How to create and use Data volumes with Docker
- How to configure basic Networking
Ready? Let’s begin.

What the heck is Docker?
Docker is a platform for Applications to be built and run in a container with all the required software packaged in it.
But you ask, what in the world is container?
Container is a Docker process that can be run on any Linux or Windows based system. It includes everything it needs to run, including System libraries, application code, application dependencies and configuration files. (You throw Docker container at a Car’s bumper and it will still work. Just kidding.). A Docker container is a mini-machine in its own right. Containers running on a system share the Operating System Kernel with other processes (including other Docker containers).
Tip: You can list all the Docker containers running your system by running the command
docker ps
Let’s take a look at the diagram below, which shows how various components fit it.
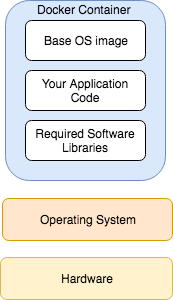
To contrast this with how software applications are traditionally run, look at the image below.
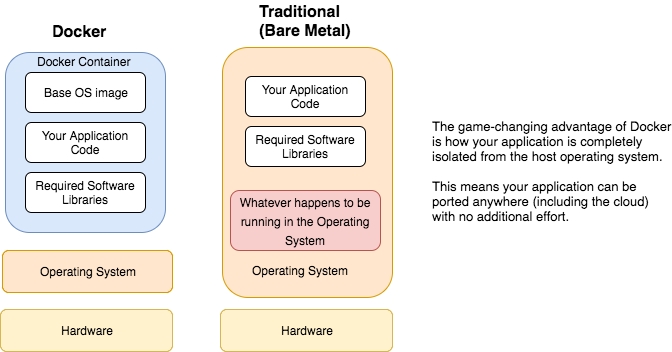
At this point, you may be wondering, ‘Wait a minute. I’ve seen this before. Are you not talking about virtualization? Vmware and stuff?‘
Not really. Simply put, vmware visualizes the underlying hardware resources. But Docker visualizes the Operating System.
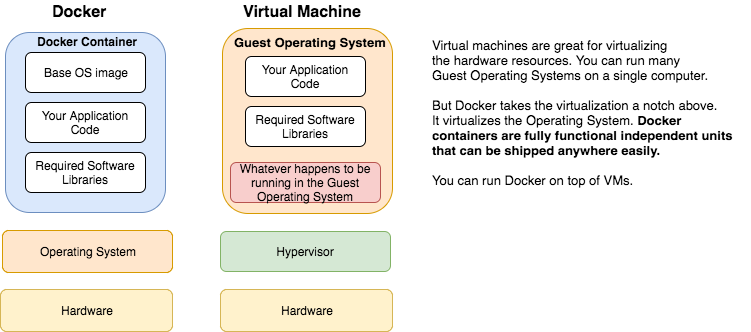
At this point, if you have been doing Application Support for a while, one striking advantage should be obvious to you: consistency of environments. Think about how many times you have been told by the development team: ‘Oh, but it works in my local Dev environment. Something must be wrong in production servers. May be a jar file is missing in the classpath in Prod?, Or may be the Java minor version is different in prod?’ Painful. Docker puts an end to all this environment specific mysteries.
So, to summarize: Docker is a container solution that enables building, shipping and running applications with all the required software in a single unit. The benefits include consistency across deployments, fast startup, flexible and developer-friendly build process.
Enough fluff. Let’s get our hands moving by actually running a Docker container.