If you are in IT Operations in any role, you have probably come across either Splunk or ELK, or both. These are two heavyweights in the field of Operational Data Analytics. In this blog post, I’m going to share with you what I feel about these two excellent products based on my years of experience with them.
The problem Splunk and ELK are trying to solve: Log Management
While there are fancier terms such as Operational Data Intelligence, Operational Big Data Analytics and Log data analytics platform, the problem both Splunk and ELK are trying to solve is Log Management. So, what’s the challenge with Log management?
Logs, logs, logs and more logs
The single most important piece of troubleshooting data in any software program is the log generated by the program. If you have ever worked with vendor support for any software product, you have been inevitably asked to provide – you guessed it, Log files. Without the log files, they really can’t see what’s going on.
Logs not only contains information about how the software program runs, they may contain data that are valuable to business as well. Yeap, that’s right. For instance, you can retrieve wealth of data from your Web Server access logs to find out things like geographical dispersion of your customer base, most visited page in your website, etc.
If you are running only a couple of servers with few applications running on them, accessing and managing your logs are not a problem. But in an enterprise with hundreds and even thousands of servers and applications, this becomes an issue. Specifically,
- There are thousands of log files.
- The size of these log files run in Giga or even Terra bytes.
- The data in these log files may not be readily readable or searchable (unstructured data)
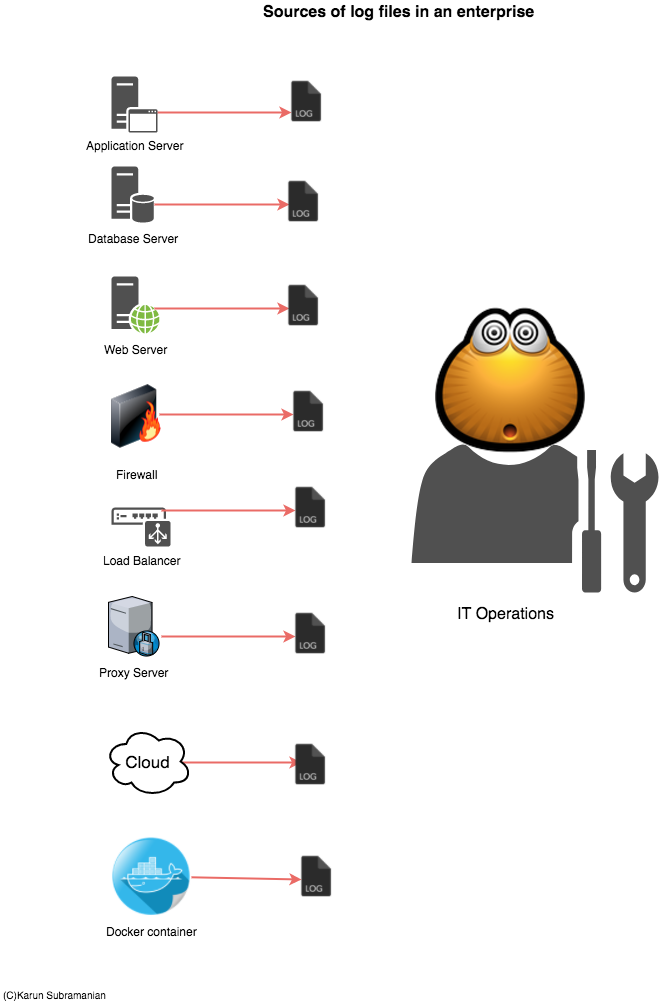
Both Splunk and ELK attempt to solve the problem of managing ever growing Log data. In essence, they supply a scalable way to collect and index log files and provide a search interface to interact with the data. In addition, they provide a way to secure the data being collected and enable users to create visualizations such as reports, dashboards and even Alerts.
Now that you know the problem Splunk and ELK are attempting to solve, let’s compare them and find how they are achieving this. I’m going to compare them in 4 areas as follows:
Technology
Cost
Features
Learning Curve for the operations team
Got it ? I can’t wait to share. Let’s dive in.

VS
![]()
Technology
Witnessing C++ vs Java has never been more exciting
While Splunk is a single coherent closed-source product, ELK is made up of three open-source products: ElasticSearch, LogStash, and Kibana.
Both Splunk and ELK store data in Indexes. Indexes are the flat files that contain searchable log events.
Both Splunk and ELK employ an Agent to collect log file data from the target Servers. In Splunk this Agent is Splunk Universal Forwarder. In ELK, this is LogStash (and in the recent years, Beats). There are other means to get the data in to the indexes, but the majority of the use-cases will be using the Agents.
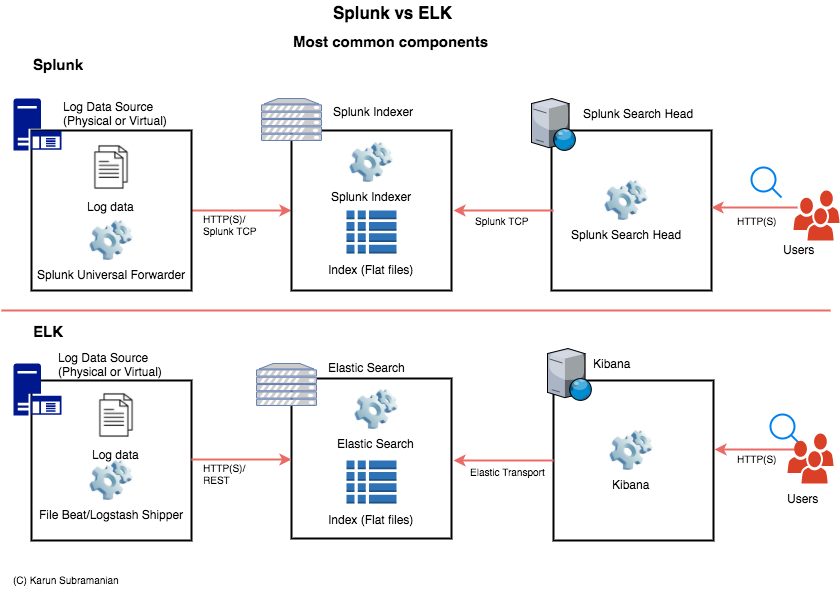
While Splunk uses a proprietary technology (primarily developed in C++) for their indexing, Elastic Search is based on Apache Lucene, an open source technology written fully in Java.
On the Search interface side, Splunk employs a Search Head, a Splunk instance with specific functions for searching. ELK uses Kibana, an open source data visualization platform. When it comes to creating visualizations, in my opinion, Splunk makes Kibana look plain. (Note: It is possible to use Grafana to connect to ELK to visualize data. Some believe Grafana visualizations are richer than Kibana). With recent versions of Kibana, you also have Timelion, a time series data visualizer.
For querying, while Splunk uses their proprietary SPL (Splunk Porcessing Lanugage, with syntax that resembles SQL-like statements with Unix Pipe), ELK uses Query DSL with underlying JSON formatted syntax.
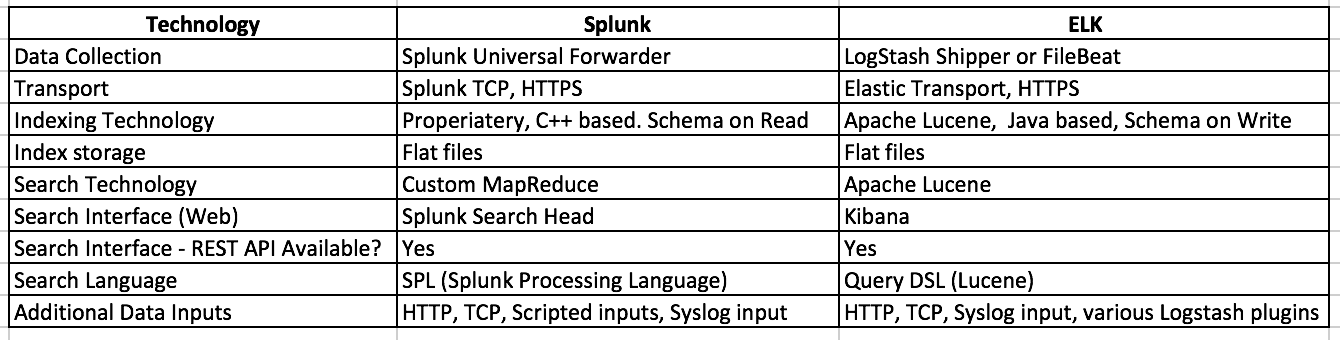
Let me summarize the technical info in the table below.
In the end
Both Splunk and ELK are fundamentally very sound in Technology. Though one can argue one way or the other, the longevity of these two products in the marketplace prove that they both are indeed superior in their own way. However, Splunk differs in the crucial Schema on read technology.
With Schema on read, there is minimal processing required before indexing. In fact you can throw anything at Splunk as long as Splunk can determine the Host, Source (File where data is coming from) and Source Type (a meta field that helps Splunk to determine the type of the log file, manually/automatically determined), it can ingest and index the data just fine. Most fields in the data are generally determined ONLY at the search time.
However, with ELK, you must provide the field mapping ahead of time (before indexing). One can certainly argue that this is not necessarily bad. But I’m going to leave it up to the community to decide.
Cost
Is Open-Source really free?
Cost of the software: ELK is free. Splunk is not.
Splunk’s license fee is based on Daily Log Volume that is being indexed. For example, you may buy a 1TB license which will let you ingest up to 1TB per day. There is no cost for keeping the historic data. It is only the daily volume that counts (the License Meter resets at midnight every day). Further the cost is NOT based on the number of users or number of CPU cores either. You can get either a Term license, which you pay per year. Or you can get a perpetual license, which is just one time fee plus annual support fee (if any).
I’m unable to give you a dollar figure as it greatly various based on geographic location of your business, and obviously on the data volume (and the sales team you are working with :-)). But in general, compared to other commercial products in the market (SumoLogic, Loggly, Sematext etc), Splunk *may* be on the expensive side. (Again, too many variables to give you a black-and-white answer).
ELK is open source. You pay nothing for using the software.
But, and this is a big but, the cost of ownership is not just the cost of software. Here are other costs to consider.
- Cost of Infrastructure. Both Splunk and ELK would require similar hardware infrastructure.
- Cost of implementing the solution. This is a big one. For example, when you purchase Splunk, you might get some consulting hours that you can use to implement your solution. With ELK, you are on your own.
- Cost of ongoing maintenance: This can also be a big one. Once again, you might get some support hours from Splunk, but with ELK, you are on your own.
- Cost of add-ons and plugins: Both Splunk and ELK have plugin/add-on based solutions that extend the fuctionality. Some are free and some are not. For example, you will have to pay for Shield (ELK Security) and ITSI (Splunk IT Service Intelligence)
In the end
Yes, Open source is free. But is it free, as in free ? The biggest problem you will face, as an evangelist of ELK in your organization, is coming up with a dollar amount of the cost. As for Splunk, you have to be able to convince your organization of the cost. At least in this case, the cost is predictable.
Features
Looking for somethin? There is an app for it.
Both Splunk and ELK have myriad of features. When I say feature, it can be any of the following:
- Support for a certain type of data input. For example, does it allow data input via HTTP, or a script ? So, earlier when I said both Splunk and ELK employ an agent to collect data, I lied. Both the products support several other means of getting data in.
- A data visualization functionality. For example, does it allow creating custom dashboards, reports, etc? How feature rich are they ?
- Integration with other products/frameworks. For example, can it send/receive data from APM products such as NewRelic, Dynatrace or AppDyanmics ? Can it send/receive data from Hadoop ? Both the products integrate well with many major platforms.
- Security Features: Does it support Role Based Auth, two-way SSL or Active Directory Integration? With Splunk, security is available out of the box. But with ELK, you pay for Sheild (or Xpack in the recent versions)
- Data manipulation: How easy is it to modify the data being ingested? Can I mask sensitive information readily? Splunk provides powerful regular expression based filters to mask or remove data. Same can be achieved with Logstash in ELK world.
- Extensibility: Can we easily extend the product by writing our own solutions?
- Metrics Store: Indexing text (log files) is one thing. But indexing Metrics (numerical data) is another thing. The performance of indexing and search is astronomically higher on a Time series Metrics index. Splunk has introduced this in their Version 7.
- Agents Management: How are you going to manage hundreds or thousands of Beats or Splunk Universal Forwarders ? While ansible or chef can be used with both the products, Splunk has an advantage of letting you manage the universal forwarders using their Deployment Manager (A Splunk instance with a specific function)
In the end
Since both ELK and Splunk have a strong user community and good extensibility, there is no shortage of plugins and add-ons. (In Splunk world, there is the notion of apps).
splunkbase.splunk.com (https://splunkbase.splunk.com/)
Elastic Search Plugins (https://www.elastic.co/guide/en/elasticsearch/plugins/current/index.html)
Learning Curve for the operations team
From 0 to 60mph in 3 seconds. Really?
Both Splunk and ELK have massive product documentation. Perhaps too much documentation if you want to get started rapidly. The learning curve for both the products is steep.
For both the products, a solid understanding of Regex (Regular Expressions), Scripting (Shell/Python and the like) and TCP/IP is required.
For performing searches, you must learn SPL (Splunk Processing Language) for Splunk, and Query DSL for Elastic Search. SPL is like unix pipe + SQL. It has got tons of commands that you can use. With Query DSL, the queries are formatted in Json. In both the products, the search language can easily overwhelm a new user. Just because of the sheer amount of features that SPL provides, Splunk can be much more intimidating than ELK. (In fact, there are 143 search commands in SPL in their Splunk Enterprise 7.0.1).
Creating visualizations also require some learning. Here again, Splunk proivdes more features and might look more intimidating than Kibana for a new user. Note that you can also use Grafana to connect to ELK to visualize data.
Perhaps the biggest hurdle you will face with Splunk is the server side Configuration and Administration. The entire product is configured using bunch of .conf files. One will need intimate knowledge of the specification of these configuration files in order to implement and support Splunk. While ELK does require some reading on server side setup, it’s not nearly as much as Splunk.
In the end
Spunk does have a steeper learning curve compared to ELK. But whether it is a showstopper for you or not is something you have to decide. You will have to invest in few resources with solid Splunk experience if you want to implement and support the solution correctly.
So, there you have it. Splunk Vs ELK at a super high level. I haven’t gone deep in technical aspects for brevity. But there is plenty of documentation for both Splunk and ELK online. Just get lots of coffee before you begin 🙂
Let me know what you think.
Happy Monitoring !
Sua matéria é excelente, e me ajudou a tomar uma decisão importante em relação as duas ferramentas, o custo previsível e suporte foram os aspectos fortes nessa tomada.
Com certeza usarei o Splunk
Obrigado.
very useful and keep continue.